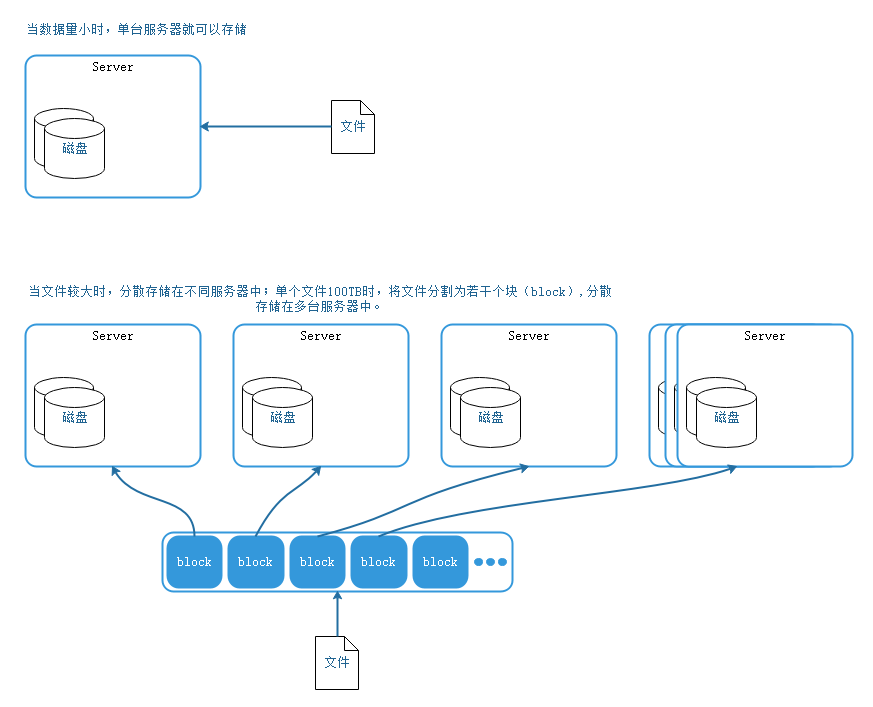
什么是Block?
物理磁盘中有块的概念,磁盘的物理Block是磁盘操作最小的单元,读写操作均以Block为最小单元,一般为512 Byte。文件系统在物理Block之上抽象了另一层概念,文件系统Block物理磁盘Block的整数倍。通常为几KB。Hadoop提供的df、fsck这类运维工具都是在文件系统的Block级别上进行操作。
HDFS的Block块比一般单机文件系统大得多,默认为128M。HDFS的文件被拆分成block-sized的chunk,chunk作为独立单元存储。比Block小的文件不会占用整个Block,只会占据实际大小。例如, 如果一个文件大小为1M,则在HDFS中只会占用1M的空间,而不是128M。
为什么HDFS的Block这么大?
HDFS读取文件时,需要定位Block的位置,如果Block设置得太小,就会导致Block的数量非常的多,在定位所有Block的时候就会非常耗时。假设定位到Block所需的时间为10ms,磁盘传输速度为100M/s。如果要将定位到Block所用时间占传输时间的比例控制1%,则Block大小需要约100M。但是如果Block设置过大,在MapReduce任务中,Map或者Reduce任务的个数 如果小于集群机器数量,会使得作业运行效率很低。HDFS将Block大小设置为128MB,是为了最小化查找(seek)时间,控制定位文件与传输文件所用的时间比例。
PS:你也可以自己根据业务情况设置
使用Block抽象有什么好处?
使用Block拆分,可以使单个文件大小超过磁盘大小,使构成文件的Block分布在整个集群。lock的抽象也简化了存储系统,对于Block,我们无需关注其权限,所有者等内容,因为这些内容都在文件级别上进行控制的。
Block作为容错和高可用机制中的副本单元,即以Block为单位进行复制。
Block的复制
我们在文章初识HDFS:Hadoop分布式文件系统中提到过——HDFS是运行在廉价硬件上的分布式文件系统,并且硬件故障是不可避免的。
如下图的存储方式,假如上图中任意一台DataNode宕机,这个文件将无法完整读取。
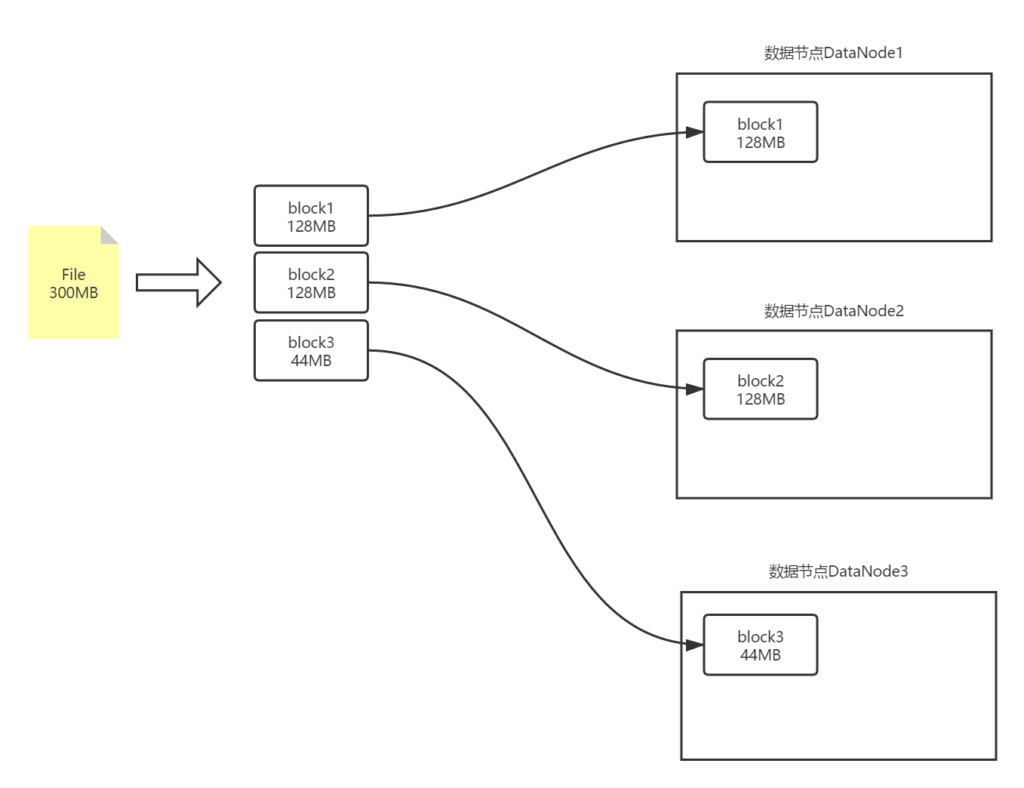
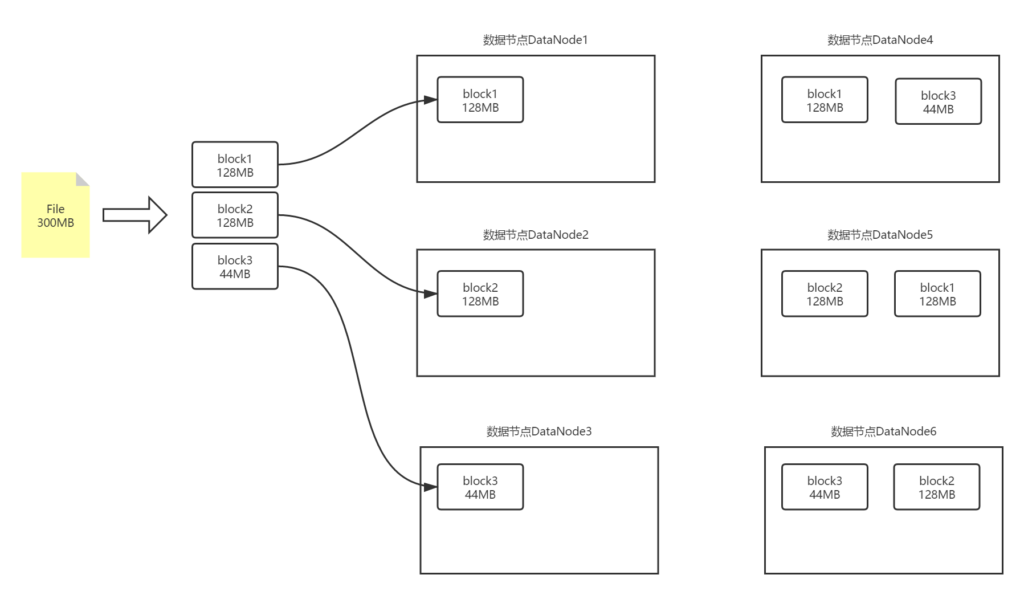
为了解决这个问题,HDFS引入了Block副本的概念。即一个Block在不同的DataNode中保存多份,这样就算其中一个节点宕机了,其他节点中的Block副本也能保证数据的完整可读性。如下图:
机架感知策略
机架感知是HDFS为了应对整个机架(Rack)断电或者断网时服务不受影响而采取的一种Block存储策略。
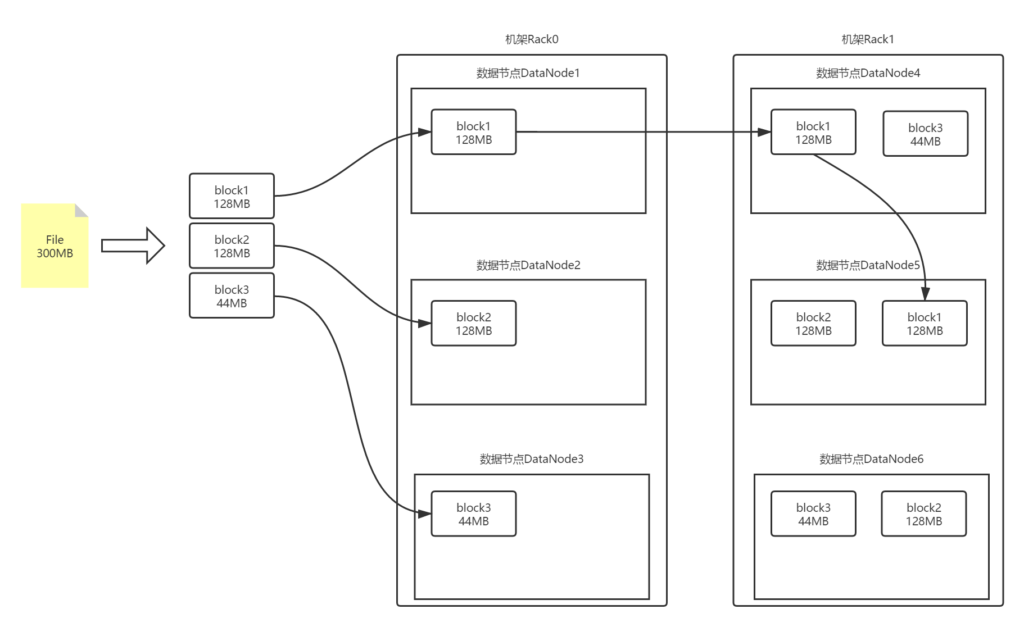
Block副本的存储策略是:
- 如果本地机器是DataNode节点,那么第一个Block副本存储在本地机器上,否则将在本机器同机架中随机选取一台DataNode机器存储;
- 第二个Block副本会存储在另外一个机架(此处称为Rack1)的某个DataNode节点上;
- 第三个Block副本会存储在Rack1机架的另一个DataNode节点上。
- 如果你设置的Block副本数超过3个,那其余的副本将在保证每个机架的副本不超上限((副本数-2)/机架数+2)的情况下,随机分布在集群中。
第二个Block副本存储在不同的机架中解决了整机架断电或断网的隐患;而第三个副本存储在与第二个副本同机架的节点上,是为了减少再次跨机架传送所带来的时间成本。
总结
Block是HDFS为了跨机器存储大文件而抽象出来的概念,它使得存储超大文件成为了可能。副本机制保证了数据的安全性。Hadoop生态中,大部分计算程序都是以Block为基本单位进行运算的,所以Block在HDFS是非常重要的概念。
14,878条评论