前言
现在业内使用的大多数分布式框架都是主从结构,HDFS也不例外。在HDFS框架中,我们可以理解NameNode是主,DataNode为从,但是HDFS框架并非只有这两个组件,今天我们就来聊一聊HDFS中的最强辅助——SecondaryNameNode。
NameNode的工作
在了解SecondaryNameNode之前,我们先来看下NameNode是做什么的。在一个文件系统中,有一个元数据的概念,关于一个文件的路径/名称/大小/修改日期等描述信息,我们称之为这个文件的元信息。在windows中我们右键文件选择属性,看到的就是元数据。
文件系统中,为了便于管理存储介质上的,给每个目录、目录中的文件、子目录都起了名字,这样形成的层级结构,称之为命名空间。因为同一个目录中不能有同名的文件或目录,所以在一个命名空间中,通过目录+文件名称的方式能够唯一的定位一个文件。而这些数据也都属于元数据的一种。
在HDFS中,命名空间就存储在NameNode的内存中。另外还使用一个称为EditLog的事务日志来永久记录文件系统元数据发生的所有更改。熟悉mysql的朋友,可以参考一下binlog。例如,我们在HDFS中创建一个新文件会导致NameNode在EditLog中插入一条记录来表明这一点。同样,更改文件的操作也将被记录到EditLog中。NameNode将EditLog保存在本地主机的磁盘上,如果NameNode宕机重启后,内存中的元数据信息丢失,也可以通过逐条读取EditLog记录到内存中来恢复元数据。虽然NameNode使用EditLog解决了内存中元数据易丢失的问题。但是EditLog会随着时间变得越来越大,重启后恢复所需要的时间也会越来越长。为了避免这种情况,HDFS引入了为检查点机制(checkpoint)。NameNode定期将内存中的命名空间镜像写到磁盘中名为fsimage的文件中,待到恢复时只需将最近的检查点的fsimage文件读取到内存中,再执行这个检查点之后的EditLog即可恢复命名空间数据。
最强辅助SecondaryNameNode
尽管我们有了EditLog和检查点机制,但是当HDFS数据量大的时候,两个检查点之间的数据依然会非常大。NameNode重启后恢复期间,HDFS的服务是不可用的,这使得我们不得不再次寻求更快的恢复速度,所以我们有了SecondaryNameNode来辅助NameNode。
首先,创建检查点checkpoint的两大条件:
- SecondaryNameNode每隔1小时创建一个检查点
- Secondary NameNode每1分钟检查一次,从上一检查点开始,edits日志文件中是否包括100万个事务,也会创建检查点
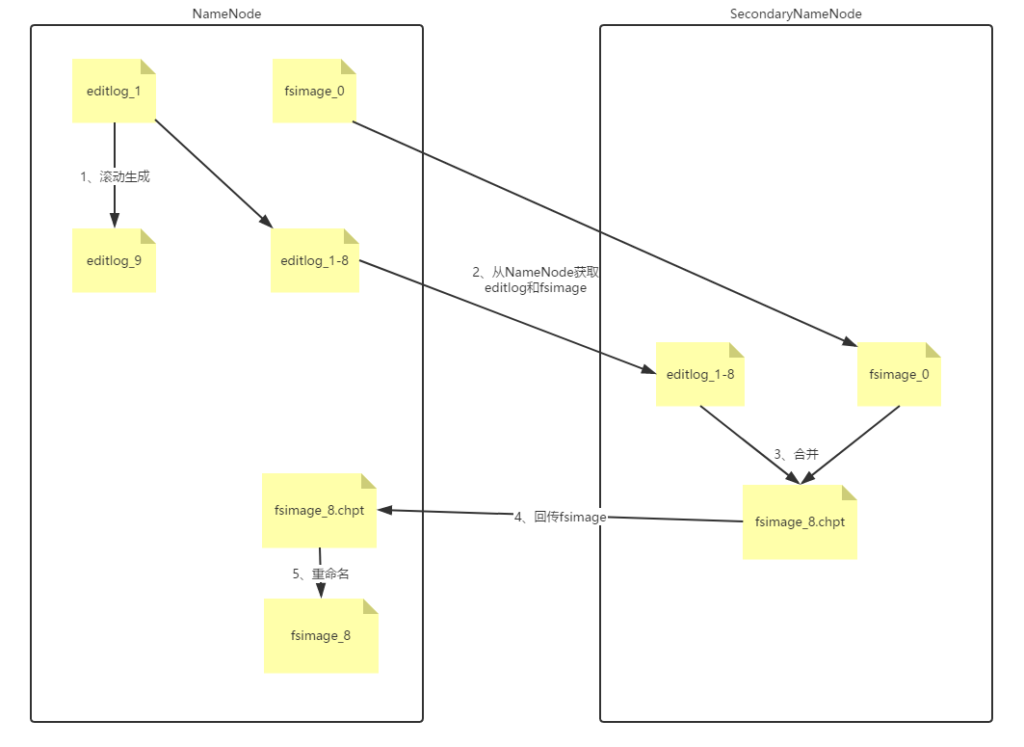
当满足创建检查点的条件时,SecondaryNameNode首先请求原NameNode进行EditLog的滚动,这样新的编辑操作就能够进入新的文件中;再通过HTTP GET方式读取NameNode中的fsimage及EditLog;然后,SecondaryNameNode读取fsimage到内存中,然后执行EditLog中的每个操作,并创建一个新的统一的fsimage文件;再通过HTTP PUT方式将新的fsimage发送到原NameNode;随后NameNode用新的fsimage替换旧的fsimage,同时系统会更新fsimage文件到记录检查点的时间。这个过程结束后,NameNode就有了最新的fsimage文件和更小的edits文件。因为合并操作需要占用大量的CPU时间,并需要占用与原命名空间一样甚至更多的内存,来执行合并操作,所以将这个操作放到SecondaryNameNode而不是直接在NameNode上完成。
总结
SecondaryNameNode是为了让NameNode更快处理fsimage与EditLog的合并而诞生的。为了完成这个操作,SecondaryNameNode往往拥有和NameNode同样的性能。因此称它为最强辅助也不足为过啦。
关注 零一大数据,获取更多技术干货
